Good day and welcome to Future Visible's blog on all thing's Data Science and Development.
Today's post is about how we can integrate the exciting new data science discipline of Process Mining with the more established practise of Behaviour Driven Development (BDD), as part of the AGILE software development process.
As readers will be approaching these subjects from two very different backgrounds, we will begin by defining these terms.
What is Process Mining?
Process Mining is a very exciting emerging area of data science that concentrates on the understanding of business processes.
A traditional model of understanding processes is to play out the process from what we think we know of it from existing business knowledge or required future behaviour. Of course, this may be very different from how a process operates in practise.
Process Mining takes a play in approach, reverse engineering actual business processes as they are in the real world from event log data, rather than relying on theoretical models to describe them. It is coming into it's age in the emerging world of the "Internet of Things", that will mean that the existence and access to event logs data for all parts of a complex process will become much more comprehensive than it has been until now.
After ingestion of the log data in an ETL process, tools such as ProM and Disco can reverse engineer the process flows. An example of a process flow created using Fluxicon's Disco tool is shown below:
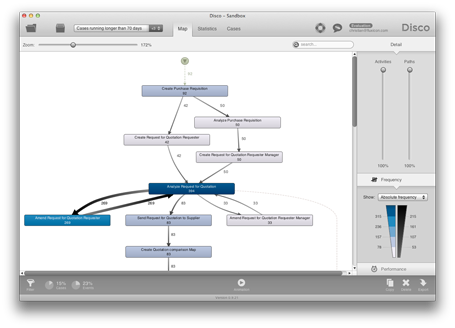
Image reproduced with kind permission of Fluxicon.
I would stress that Process Mining has far more powerful and sophisticated applications than just the one shown in this blog. For those interested, I very strongly recommend the Coursera course provided by the Eindhoven University of Technology.
What is BDD?
For those of you from a Process Mining background, Behaviour Driven Development, or BDD, is a way of describing business logic and running that logic against testable code. It is therefore a classic play-out mechanism for understanding of and building of business requirements by IT teams.
The language syntax of BDD is called Gherkin, implemented via Cucumber, and it is very extensively used in the AGILE software development process. It's great strength is that creates terse behavioural steps to describe business process in literal language that can be understood by both product owners, business analysts and developers:
Feature: Megacorp needs a new caseworkering system
Scenario: An application must arrive into the new application bucket when it is submitted.
Given the system is in state 'X'
When I perform an action 'Y'
Then I expect the result 'Z'
Each Given, When, Then step is mapped to an underlying piece of test code that performs the actions required. Classically BDD is used for automated UI testing of web applications, but it is also used for API testing, so there is no reason it's use cannot be extended to the 'Internet of Things' in future as process mining comes into it's own.
BDD is effectively self-documenting acceptance test code. Once written, BDD forms living documentation as it runs continually against the application build. Therefore, it should not 'rot' in the way static documentation is prone to do.
Process Mining and BDD - A Marriage Made in AGILE?
Both Process Mining and BDD clearly have great strengths, but also significant weaknesses. A mined process can only ever be as good as the event log coverage programmed into applications in the first place, whereas BDD is used to build applications based on the theoretical business process, not the actual one.
In a perfect world, the theoretical process, actual process and event logs would cover each other perfectly. We do not live in a perfect world.
Instead, when designing our new application or feature these relationships are highly likely to be an imperfect fit: we can imagine them in terms of as a Venn diagram, as shown below.
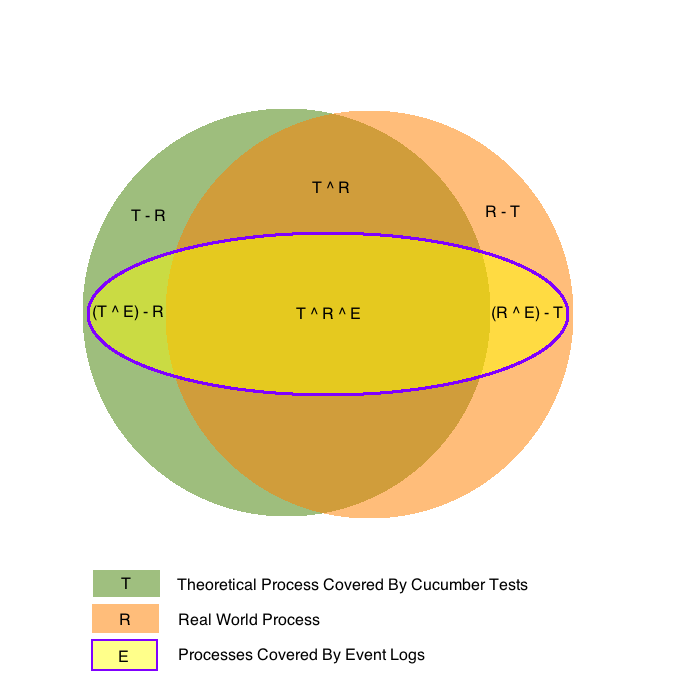
For those not familiar with set theory notation, a short guide can be found here.
Imagine as an example that your AGILE team is building a web application for a complex company process. This process has 16 events that we can signify using the letters 'A' to 'P'.
When designing upcoming user stories, your business analyst, the testers (or developers-in-test) and a developer - together known as The Three Amigos - sit down and map out a BDD scenario:
Feature: Megacorp needs a new CRM system
Scenario: A customer request must be processed upon submission.
Given the system is in a state 'A'
And also in a state 'X'
When I perform action 'D'
Then I expect to see result 'E'
When I perform an action 'F'
Then I expect to see result 'H'
And I expect to see result 'I'
When I perform an action 'K'
Then I expect to see result 'O'
And I expect to see result 'P'
Unfortunately, the real-world process is not perfectly understood - 6 steps are missing, and the second step 'X' is not even represented in the real process! This gives rise to BDD cucumber scenarios that do not entirely represent the real world process (set T in the Venn diagram above) and parts of the real process (set R) that we have no representation for in our application requirements or testing. To compound this problem, the logging written by the developers is incomplete and only covers a small part of the theoretical and real-world processes (set E).
BDD AS a Log Conformance Checker
As a first step in eliminating the gaps in our understanding, let us run our BDD scenario and then mine the process from the produced event log. This will create a process from the subset T ^ E in our Venn diagram. Clearly, this check should be performed as part of testing the story within the AGILE cycle, well before it goes live.
Below is our mined process produced from running a single BDD scenario representing the new business feature.
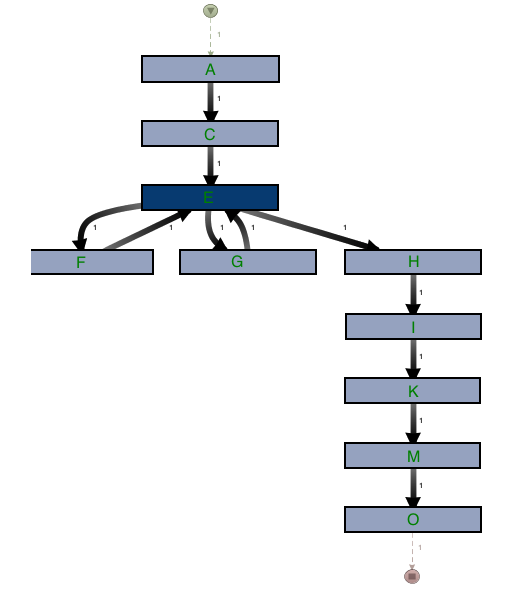
We can then compare the steps in the BDD scenario to the mined process generated from event log data. From this we can deduce the level of conformance the log has to the theoretical process by mapping each event in the logs against the corresponding BDD step:
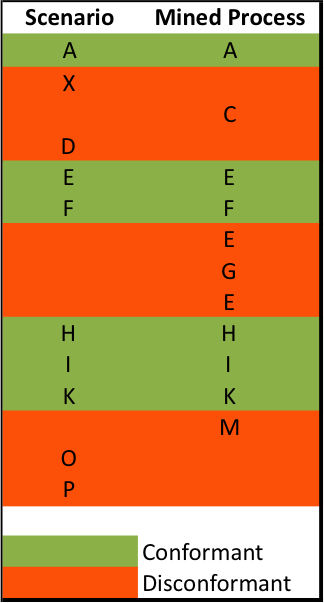
Clearly we have BDD Steps that have no corresponding events in the mined process (T - E in our Venn diagram). The extent of the discrepancy means the user story has failed to pass the testing phase and must now go back to development so that the missing event log data can be added to the application. Note, also, that the mined process produced from our logs may contain a level of granularity in events not represented in our BDD scenarios (~T), which we can choose to represent either as extra BDD steps or as extra test expectations within those steps.
Once this information has been added and the story again passed from development to testing, the scenario is re-run and subsequently the mined process from the augmented logs is produced. Once the scenarios and the mined process (and therefore the level of logging) are judged to have reached the required level of conformance, assuming all other testing is satisfactory the story can proceed towards sign-off and ultimately released into production.
At this point, our logging (set E) should cover the entire set T in our Venn diagram, and set T itself may have been expanded to cover more events. Remember, however, that we still have no actual knowledge of what the real-world process (set R) is at this stage and to what extent is overlaps with our theoretical set T.
Refactoring BDD From Our Mined Real World Process
Once our story goes live, then the real fun begins. Process Mining obviously comes into it's own on real world processes, and a great deal of it's productive appeal is to reveal discrepancies between the way we think a process should work (T) and how it actually works (R). As well as resulting from poor understanding of the process on the part of analysts and product owners, these discrepancies can also arise from poor working practice on behalf of operatives: on our Venn diagram this represented by all areas in sets T and R outside the intersection of those two sets.
Process Coverage
Process Mining of the live application therefore gives an objective understanding of the Process Coverage of our BDD acceptance tests, something that historically has been missing from the software development process.
Having examined our real-world mined process, we can then either play new user stories to adjust our expectations of the system (and in the process our cucumber BDD scenarios) and / or bring our real-world working practises into line. Our cucumber tests and the real-world process are now as conformant as they can be. However, note that steps 'B' and 'N', represented by area R - (T u E) in our Venn diagram, i.e. those parts of the real-world process neither predicted by our scenarios or represented in the event logs, may remain undiscovered.
Slicing Our Cucumbers
As discussed in our introduction to BDD, cucumber tests are fantastic for describing business requirements for new features and as acting as living documentation of existing ones. However, they do have their drawbacks from a development point of view: They tend to be 'fat', that is slow running, cumbersome and prone to breaking yielding false negatives that fail the application build. As an application matures and the number of tests grows, they start to exert a major drag on the release cycle.
Consequently, developers start to exert major pressure on the test team to reduce the number of cucumber tests, usually by 'pushing them down' the stack into integration or unit tests. However, a major downside of doing so is that visibility of business logic is lost from the system.
Process Mining can be a major benefit in this situation. As a powerful tool for promoting visibility of business logic it can lessen the need for maintaining that visibility via cucumber scenarios. Therefore, cucumber tests can be much more safely replaced, particularly in mature parts of the application that are unlikely to be worked on in the future.
Secondly, when designing cucumber tests, as time goes by developers start to implement short cuts in setting up system state in order to make the tests faster and more reliable. However, this obviously means that part of the tests no longer implement the real-world process at all. Again, checking the short cuts you have implemented against mined logs of your tests can help to assure developers that they haven't introduced any nasty side-effects in the process.
Conclusion: Introducing 'The Four Amigos'
I hope I have convinced you how the immensely exciting new area of Process Mining is not just a post-development tool, but can - and should be - tightly integrated into the AGILE development and testing cycle via Behaviour Driven Development.
We can also see that in future, the behavioural testing steps in the AGILE cycle will increasingly involve business analysts, developers-in-test/testers, developers and a process miner.
It's time to welcome the Process Mining Hombre into the AGILE team: long live the 'Four Amigos'!
Author: Dr. Andrew Tekle-Cadman
http://www.linkedin.com/in/andrewcadman